Glossaries: improvements
Some changes designed to make scripts for glossaries layout better have been introduced in DGT-OmegaT 3.4 (when it was DEV version). Features indicated with  are available in 3.5-STABLE, those marked with
are available in 3.5-STABLE, those marked with  are still experimental and present only in 3.7-DEV or eventually in 3.6-BETA.
are still experimental and present only in 3.7-DEV or eventually in 3.6-BETA.
Tooltips and collapsable parts
In technical discussion about glossary layout, two interesting ways to hide big text in the glossaries pane were proposed: tooltips, and text which is deployed on mouse over, which I would call collapsable part. Both are introduced in DGT-3.4 update 1.
In the Groovy code, this works more or less like an XML markup:
- For tooltip, you will use a method startTooltip(txt) with the text to appear as a tooltip in the parameter, then you continue to add the visible text, and you call a method endTootip() without parameter, as a mark to say where the text which receives the tooltip ends.
- For collapsable text, you will use startHiddenPart(prefix, suffix) where prefix and suffix are the text which appears when the hidden part is not deployed; then you add the hidden text, and you conclude by endHiddenPart(). When OmegaT will render an entry it will display only prefix and suffix, but if you click on it, the hidden part is inserted between them (they are still visible).
Actually this solution has some known problems: hidden parts are not compatible with clickable links in the comments, and mutiline comments (like the ones produced by TBX glossaries) are not properly hidden. That's the reason why this should be considered as experimental for the moment.
Define sort criteria
Initially OmegaT uses the following order for glossary entries:
- priority (put entries from writeable glossary before anything else);
- string length (longest entries first);
- case insensitive order in the source;
- case sensitive order in the source;
- order in the target
This choice was sometimes discussed in the mailing lists but did not change for more than 5 years.
DGT-OmegaT 3.6 and 3.7 enable to define the order you prefer:
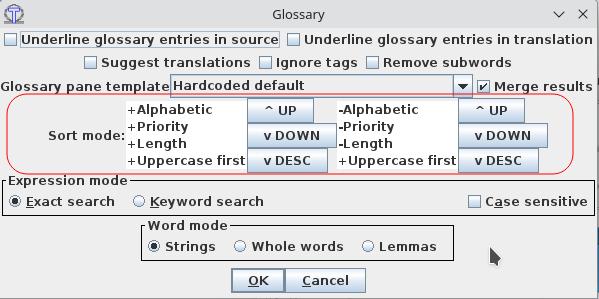 |
First criteria is for ordering by source of the entry, second criteria is for ordering target entries (this second criteria is only used if "Merge results" is active) You can select a criteria and click "Up" or "Down" to move it on the list. Button "Desc" enables to switch between ascending and descending order, which appear as "+" or "-" before the criteria name. Note that alphabetic order, contrarily to standard OmegaT, is language-dependent: in particular, behaviour against accented letters would differ from french (ignoring them at first read but using them if two strings are identical) to swedish (considering accented letters at end of the alphabet) |
Indexation with Lucene
The possibility to use Lucene Indexes, initially made for translation memories, now works also for glossaries. Such glossaries are not necessarily faster than text files but they are not loaded in memory, meaning that you can use gigabyte glossaries without any problem even with low RAM consumption.
Architecture of Glossaries API
Changes in glossaries API:
- Unification of glossary types: now, even file readers (GlossaryCSVReader, GlossaryTSVReader, GlossaryTBXReader) are also implementations of the enlarged interface IGlossary
Reason: enable next point - In GlossaryEntry, save the origin as an IGlossary rather than a simple string
Reason: in groovy scripts, this enables to choose easily between short name (only file name) and long name (with path); in the future, for more complex glossaries (such as TBX) it may be possible to access some meta-data (present in the header for example), either to display them or to implement different algorithm for "comment" depending on which dialect is used - GlossaryEntry does not anymore store boolean "priority", this is calculated by the glossary manager
Reason: now a plugin cannot decide anymore whenever it should answer true or false for this field: responsability to decide whenever an entry has priority or not is left to the glossary manager - Separation between class for glossary entry stored and class for glossary entry displayed.
Reasons:- As for previous point, now a glossary plugin cannot return merged entries anymore. The decision of merging is done by the glossary thread, not by the plugin
- This takes less memory, because stored entries do not store arrays;
- Stored entry is not a final class: more complex glossaries, such as TBX, can store complex data as Java maps or structures, rather than in a string, and the layout script can decide which properties it wants to display or not
- In stored entry, distinction between note (pure text), properties and "comment" (arbritary combination of properties)
Reason: better support for TBX format. In the scripts, user can select which properties he want to see or not
TBX improvements
Reading
First of all, TBX is now read as a StaX stream, rather than using JAXB: this saves memory and time, because the JAXB objects were until now created and used only once.
The new reader also has support for the new TBX 3.0, almost in the DCA style (attributes, similar to TBX 2). Files in TBX 3.0 / DCT style will be read but without attributes.
TBX dialects
Most people are not aware about this, but TBX is not a simple XML schema which is followed by all instances: the schema describes only the basic structure named "TBX core", enabling to have properties, but then the list of existing properties must be described in a kind of sub-schema named XCS (extensible constraint specification) .
When OmegaT implements an option like "display context", not sure they realize that this notion does not exist in TBX itself, but only in default and in TBX Simple, which are only the most common XCS dialects. Now it is possible in the groovy script to ask the glossary for its XCS dialect and implement a distinct behavior for the different dialects you frequently use.
Add new comment